Hello everyone! This project is one of the most popular ML projects as an entry. The dataset we’re going to work on is about the iris flower. The iris flower has three species with different qualities. These species are iris versicolor, iris setosa, iris virginica. The dataset consists of 50 samples from each of three species of Iris. Four features were measured from each sample: the length and the width of the sepals and petals, in centimeters. Sepal and petal are the part of the Iris flower.

The Steps We’re Going to Follow
Loading Dataset
Analyzing Dataset
Visualizing Dataset
Selecting Model
Spliting Dataset
Training Model
Testing Model
The website I took the dataset: https://scikit-learn.org/stable/datasets/toy_dataset.html
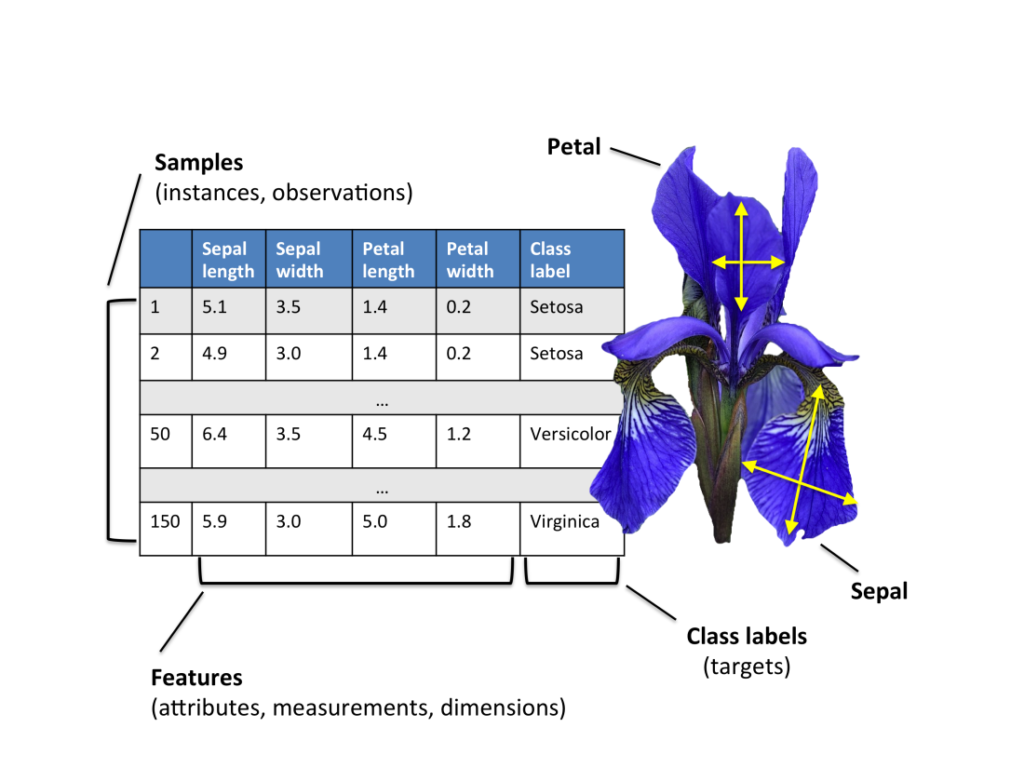
he data set consists of:
- 150 samples
- 3 labels: species of Iris (Iris setosa, Iris virginica and Iris versicolor)
- 4 features: Sepal length,Sepal width,Petal length,Petal Width in cm
1) Load Dataset

2) Analyze Data

3) Visualize Data

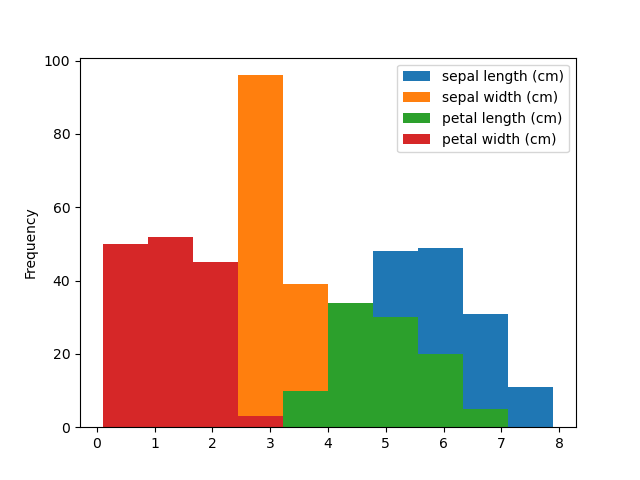
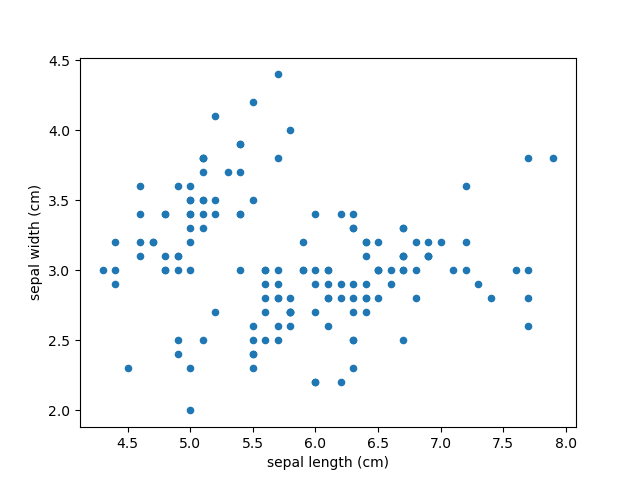
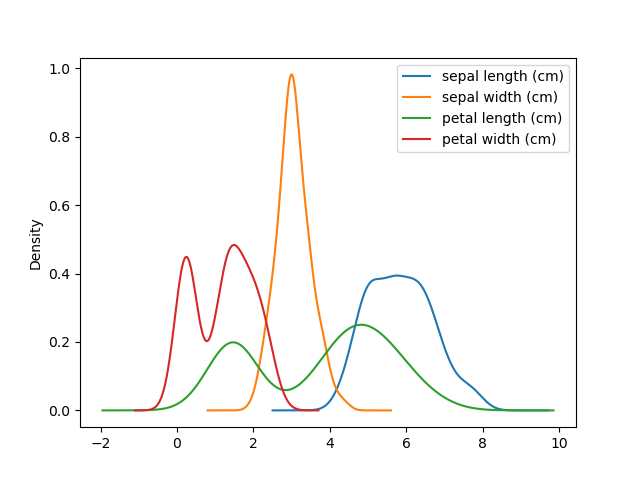
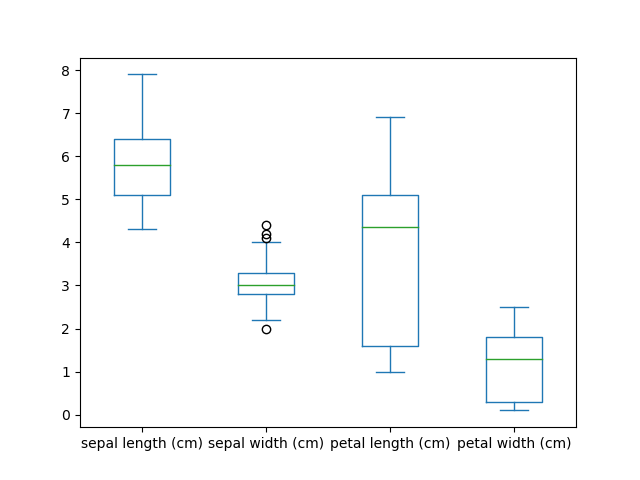
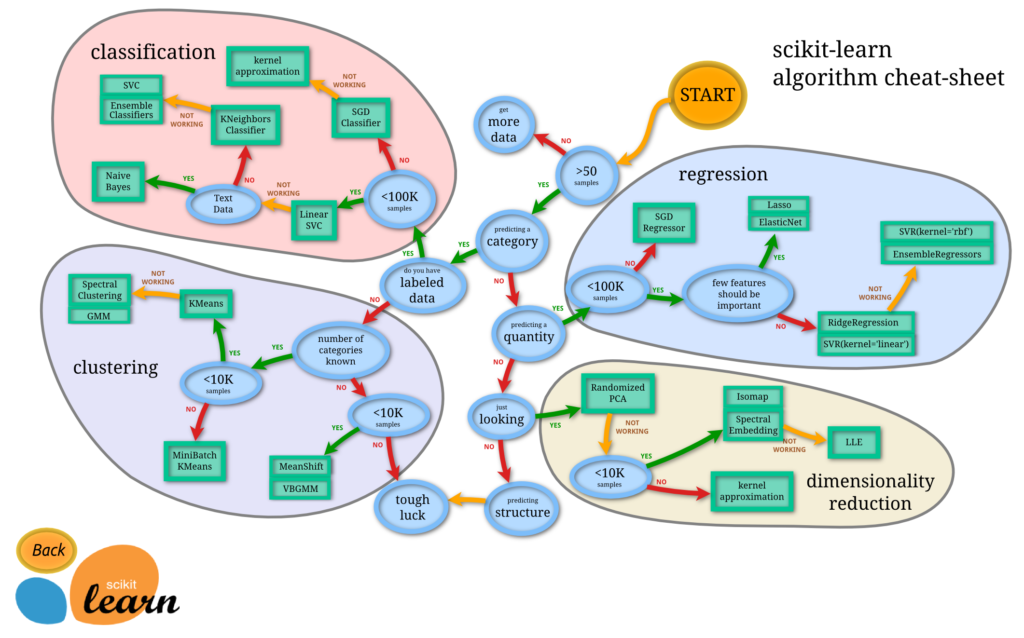
4) Select Model

To select a model this can help you with other projects:
5) Split Dataset
Since our process involve training and testing ,We should split our dataset. The dataset is splitted into training set and test set with test_size = 0.33 i.e. 67% in training set whereas 33% in the test set.

6) Train Model

7) Test Model
